

Christian Reis
on 8 September 2016
MAAS 2.0: high availability API-driven bare metal provisioning
This week, the result of over a year of work by our engineering team is concluded: the final release of MAAS 2.0 is now available for Ubuntu 16.04 LTS, and additionally from our stable release PPA.
If you’ve never heard of MAAS before, here’s an introductory slide deck from a recent presentation at the OCP Tech Day hosted by Facebook:
The highlight of this release, which brings significant evolution to the core design of MAAS, is robust High Availability (HA) for the MAAS services. This allows provisioning, DHCP and DNS services to continue to function even when one of the servers running a MAAS component fails.
A MAAS Architecture Primer
To explain how this works, it’s worth going into a bit more detail on the architecture of MAAS itself. MAAS consists of two high-level components which work together: Region and Rack. The Region controller provides the API and Web UI services, and is where all the persistent state of the deployment is recorded (under the hood, in a PostgreSQL database). It also services DNS requests and hosts the HTTP proxy when those features are enabled. The Region controller is intended to provide service to an entire datacenter, or to an autonomous subset of a datacenter.
The second component in MAAS is the Rack controller. This was previously known as the Cluster controller; it provides DHCP and PXE-boot services directly to the machines it provisions, and therefore it typically is located on the same L2 network as them, in order for it to pick up broadcast DHCP requests.
Here’s a screenshot of MAAS configured with 2 Rack controllers. In this case, the Region controller is co-located with one of the Rack controllers:
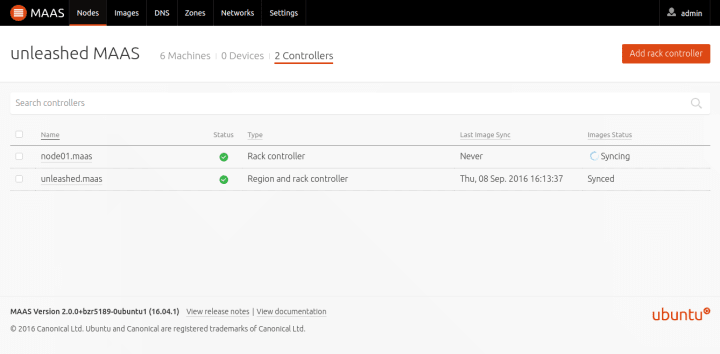
In the smallest possible configurations, the MAAS Region and Rack controllers are set up on the same machine. That’s what you get when you install the maas metapackage (by doing apt-get install maas). Colocating all services like this works great, and really reduces hardware requirements and complexity. As a deployment grows, however, it makes sense to scale MAAS out, allocating separate Rack controllers. This provides both higher scalability and, as I’ll discuss next, greater robustness through HA.
Bringing High Availability to Datacenter-scale Provisioning
This deck has a graphical overview of the MAAS architecture and the HA mechanisms which I’ll detail further below:
In MAAS 2.0, both the Region and Rack controllers can be configured in HA mode. Each of these components has a specific HA strategy:
- Multiple Region controller machines can be set up to share the same backend PostgreSQL database. They will act as a clustered service, access to which can be configured using a managed virtual IP, haproxy and/or a DNS-RR scheme. If any of the Region controller machines fail, service continues uninterrupted. Obviously, all of this assumes your PostgreSQL deployment is itself HA (but luckily Juju makes that really easy).
- Any Rack controller can be configured as a secondary controller for another Rack controller. In other words, any serviced L2 segment can have primary and secondary Rack controllers. The secondary Rack controller kicks in when the primary fails.
A Region controller failure is completely transparent. However, the Rack is special, given provisioning services like TFTP and iSCSI are inherently stateful. In the case the primary Rack fails, any machines that are mid-deployment will fail to deploy, though any new requests will be correctly routed to the secondary Rack controller, and service as a whole will continue unimpeded.
It’s worth describing why we chose to architect MAAS this way. There were two key rationales behind our HA design:
- Where HA is a requirement, having a cluster of Region controller machines for the entire datacenter is a reasonable overhead.
- Given there are likely to be multiple Rack controllers deployed in a large, critical installation, doubling the hardware requirement on this level can be quite onerous; a more scalable design has each Rack controller acting as primary for its “native” L2 segments, and as secondary for others.
It’s worth noting that in this model, the Rack controller requires L2 access to the secondary segments as well, which usually means cross-wiring that specific host to a second rack, or otherwise forwarding DHCP traffic to it. If you want less hardware overhead, that’s the trade-off.
MAAS 2.0 delivers DHCP services to networks, not cluster interfaces
If you are an existing user of MAAS, the main user-visible impact of these changes is that you no longer enable DHCP and DNS for a given cluster controller interface. Instead, you specify services for each L2 segment (referred to in MAAS as VLANs) you wish to provision and provide addresses to. MAAS tracks which Rack controllers are connected to each segment, and allows you to select a primary and a secondary. Here’s a screenshot demonstrating the Web UI for configuring VLAN services:

If you haven’t tried MAAS out yet.. Why not now?
While high availability is the headline feature, there’s a lot more in 2.0; here’s a summary of the other highlights:
- Flexible Address Ranges: with MAAS 2.0 you no longer are bound to a single contiguous pair of static and dynamic ranges; you can specify multiple ranges and reserve addresses so MAAS won’t touch them.
- Custom DNS domains and records: you can now specify multiple DNS zones, assigning nodes to the right one, and configuring additional records as needed.
- Custom DHCP configuration: while we continue to generate DHCP configuration for provisioning services, we let you specify additional configuration globally, per-host and per-subnet.
- Network model: the revamp of how we model L2 and L3 networks, a pre-requisite for High Availability, also allows us to more richly describe network topologies, and underpins the host network configuration capabilities.
- Updated API: MAAS 2.0 has a new versioned API, with clearer semantics and a more comprehensive network model.
- Service Tracking: MAAS manages a multitude of services, from DHCP to iSCSI, some of which are prone to occasional misbehaviour. (Yes, I’m looking at you, tgt.) We’ve now built in functionality (see the accompanying screenshot) to detect when services aren’t healthy so you can quickly zero in on what’s wrong.
That’s 2.0 in a nutshell. Our next release, 2.1, which is due to come out towards the end of the year, will bring better network detection and management, making it easier to figure out what’s wrong when you accidentally plugged a cable into the wrong switch port, or specified the wrong VLAN ID.
In closing, I’m impressed and humbled by the scale of the users we’ve taken on supporting in the last year, and want to make sure we continue to evolve in our mission to handle mission-critical bare-metal environments. If you are using MAAS, interested in it, or just want to discuss interesting datacenter challenges, feel free to reach out via email, IRC (#maas on Freenode) or our contact form. Thanks for your input, and specially for making us work hard to deliver something truly useful.


